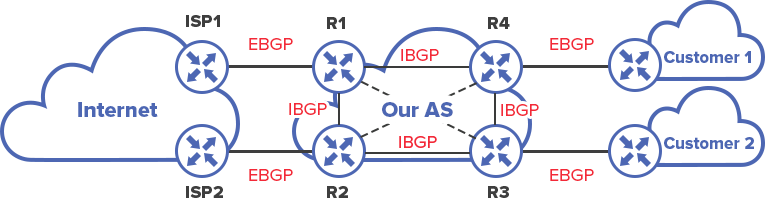
In this topology we will have two service providers (Customer 1,2) who have thier own ASN. Each customer has connectivity to a single ISP (ISP1,2.) In order for one customer to reach the other packets must be routed over eBGP - hence traversing ISP 1 and 2's ASN over BGP.
So we'll start by configuring eBGP between R2 (ASN 100) and R3 (ASN 100):
R3>
enable
conf t
int e0/1
ip address 10.254.0.1 255.255.255.252
no shutdown
router bgp 200
neighbor 10.254.0.2 remote-as 100
R2>
enable
conf t
int e0/1
ip address 10.254.0.2 255.255.255.252
no shutdown
router bgp 100
neighbor 10.254.0.1 remote-as 200
We should see an adjacancy alert appear after a little while e.g.:
*Mar 1 01:10:27.875: %BGP-5-ADJCHANGE: neighbor 10.254.0.1 Up
We can confirm our neighbors with:
show ip bgp summary
We now want to advertise our public network (13.0.0.0/24) to ISP 1 (ASN 100) - so we do this on R3 using the 'network' command:
R3>
router bgp 200
network 13.0.0.0 mask 255.555.255.0
do wri mem
We will now setup iBGP between R2 and R1 so that routes can be distributed to ASN 400 / R5:
Note: We will use a loopback address since we commonly have multiple paths to other iBGP peers - the advantage of this is if there are multiple paths to an iBGP peer and the BGP session is established over a physical link and the link goes down (or faults) the BGP session is terminated - while if using a loopback address the BGP session will remain active (and can use the other path instead.)
OK - so how would the each router (R2 and R3) know where each loopback address resides - another IGP of course - e.g. OSPF - so we setup OSPF:
R2>
enable
conf t
int e0/0
ip address 172.30.0.1 255.255.255.252
no shutdown
interface loopback 0
ip address 1.1.1.2 255.255.255.255
router ospf 1
log-adjacency-changes
network 172.30.0.0 0.0.0.3 area 0
network 1.1.1.2 0.0.0.0 area 0
network 10.254.0.0 0.0.0.3 area 0
R1>
enable
conf t
int e0/0
ip address 172.30.0.2 255.255.255.252
no shutdown
interface loopback 0
ip address 1.1.1.1 255.255.255.255
router ospf 1
log-adjacency-changes
network 172.30.0.0 0.0.0.3 area 0
network 1.1.1.1 0.0.0.0 area 0
we should be able to see each routers corrosponding loopback interface in each routing table:
do show ip route ospf
Now we can setup iBGP:
R1>
router bgp 100
neighbor 1.1.1.2 remote-as 100
neighbor 1.1.1.2 update-source loopback 0
Note: The 'update-source' statement instructs the BGP session to be initialized from the loopback adapter address.
R2>
router bgp 100
neighbor 1.1.1.1 remote-as 100
neighbor 1.1.1.1 update-source loopback 0
We can setup eBGP between R5 (ASN 400) and R1 (ASN 100):
R1>
int e0/1
ip address 192.168.10.1 255.255.255.252
no shutdown
int e0/2
ip address 172.16.20.1 255.255.255.0
no shutdown
router bgp 100
neighbor 192.168.10.2 remote-as 400
network 172.16.20.0 mask 255.255.255.0
R5>
int e0/0
ip address 192.168.10.2 255.255.255.252
no shutdown
router bgp 400
neighbor 192.168.10.1 remote-as 100
Now we want to ensure that the 13.0.0.0 network is accessable to Customer 1 (R5) - you will notice that we have to explicitly define which networks we wish to advertise to other AS's - we should firstly verify that the route is currently in our own BGP table on R1:
R1>
do show ip bgp 13.0.0.0/24
We should now be able to reach the 13.0.0.0 network from the 172.16.20.0 subnet:
do ping 13.0.0.1 source 172.16.20.1
Now we can move on to hooking up R4 and R8 to R3 with iBGP - as required by iBGP (to prevent loops) we will need to create a full mesh topology for all of our routers internally within the AS (or apply a workaround such as a route reflctor).
To do this we will start by configuring our interfaces on R3 and R4:
R3>
enable
conf t
int e0/0
ip address 172.16.0.1 255.255.255.252
no shutdown
and again we will use loopback addresses - so that the BGP session is initialized over them:
int loopback 0
ip address 3.3.3.3 255.255.255.255
router ospf 1
log-adjacency-changes
network 3.3.3.3 0.0.0.0 area 0
network 172.16.0.0 0.0.0.3 area 0
R4>
enable
conf t
int e0/0
ip address 172.16.0.2 255.255.255.252
no shutdown
int loopback 0
ip address 4.4.4.4 255.255.255.255
router ospf 1
log-adjacency-changes
network 4.4.4.4 0.0.0.0 area 0
network 172.16.0.0 0.0.0.3 area 0
We should now see the loopback interfaces within the corrosponding routing tables now.
So - lets setup iBGP:
R3>
router bgp 200
neighbor 4.4.4.4 remote-as 200
neighbor 4.4.4.4 update-source loopback 0
and on R4:
R4>
router bgp 200
neighbor 3.3.3.3 remote-as 200
neighbor 3.3.3.3 update-source loopback 0
Note: At this point I was unable to see the 17.0.0.0/24 network in the routing table - a good place to start troubleshooting is by running:
do show ip bgp 17.0.0.0/24
This will let you know whether the route has been recieved and if it is accessable - in my case I had not advertised the 10.254.0.0/30 subnet over OSPF:
R4(config)#do show ip bgp 17.0.0.0/24
BGP routing table entry for 17.0.0.0/24, version 0
Paths: (1 available, no best path)
Not advertised to any peer
100
10.254.0.2 (inaccessible) from 3.3.3.3 (10.254.0.1)
Origin IGP, metric 0, localpref 100, valid, internal
Notice the 'inaccessible' statement after the gateway.
So to resolve this we need to add the 10.254.0.0/30 into OSPF on R3:
R3>
router ospf 1
network 10.254.0.0 0.0.0.3 area 0
and recheck the routing table on R4:
do show ip route
Now we will hook up R4 to R8:
R4>
int e0/1
ip address 192.168.90.1 255.255.255.252
no shutdown
and ensure that the 192.168.90.0 subnet is advertised by OSPF:
router ospf 1
network 192.168.90.0 0.0.0.3 area 0
and on R8:
R8>
enable
conf t
int e0/0
ip address 192.168.90.2 255.255.255.252
no shutdown
int loopback 0
ip address 8.8.8.8 255.255.255.255
router ospf 1
log-adjacency-changes
network 192.168.90.0 0.0.0.3 area 0
network 8.8.8.8 0.0.0.0 area 0
and configure BGP:
router bgp 200
neighbor 4.4.4.4 remote-as 200
neighbor 4.4.4.4 update-source loopback 0
and also on R4:
R4>
router bgp 200
neighbor 8.8.8.8 remote-as 200
neighbor 8.8.8.8 update-source loopback 0
Now we review the routing table on R8 and find that there are no BGP routes! - Well we need to remember that iBGP requires a full mesh topology* and due to this we will need to hookup R8 to R3!
So on R3:
R3>
int e0/3
ip address 172.19.19.1 255.255.255.252
no shutdown
router ospf 1
network 172.19.19.0 0.0.0.3 area 0
R8>
int e0/1
ip address 172.19.19.2 255.255.255.252
no shutdown
router ospf 1
network 172.19.19.0 0.0.0.3 area 0
and then configure BGP on R3 and R8:
R3>
router bgp 200
neighbor 8.8.8.8 remote-as 200
neighbor 8.8.8.8 update-source loopback 0
R8:
router bgp 200
neighbor 3.3.3.3 remote-as 200
neighbor 3.3.3.3 update-source loopback 0
and then review R8's routing table and we should now see the BGP routes!
At the moment we have not separated our OSPF domain up - for example we don't want to have ASN 100 and 200 part of the same OSPF domain / part of Area 0 - so if I wanted I could ping a link interface of another router within another AS - although in this scenerio we only want to be able want to provide access to public IP space to Customer A and Customer B. So we will configure passive interfaces on R2 (e0/1), R3 (e0/1), R1 (e0/1) and R4 (XXXXXXXXXXXXXXXXXXXXXXXXXXX??):
R1>
ip ospf 1
passive-interface e0/1
R2>
ip ospf 1
passive-interface e0/1
R3>
ip ospf 1
passive-interface e0/1
R4>
ip ospf 1
passive-interface e0/2
This means that we will now need to ping our BGP advertised networks from another BGP advertised network i.e. you won't be able to ping a public address from a local p2p link - so for example if we wanted to access the 17.0.0.0/24 subnet from the 13.0.0.0/24 subnet we would do as follows:
R3>
do ping 17.0.0.1 source 13.0.0.1
The last step is to hook up R8 (AS 200) to R7 (AS 300) - although for AS 300 we will be injecting a default route from BGP into the IGP (OSPF.)
R4>
enable
conf t
int e0/2
ip address 192.168.245.1 255.255.255.252
no shutdown
router bgp 200
neighbor 192.168.245.2 remote-as 300
(we also need to advertise the new network (192.168.254.0/30) to our OSPF neighbors so that they can access the next hop (192.168.245.2) for the route.
router ospf 1
network 192.168.245.0 0.0.0.3
R7>
enable
conf t
int e0/2
ip address 192.168.245.2 255.255.255.252
no shutdown
router bgp 300
neighbor 192.168.245.1 remote-as 200